AI検知のやりかた
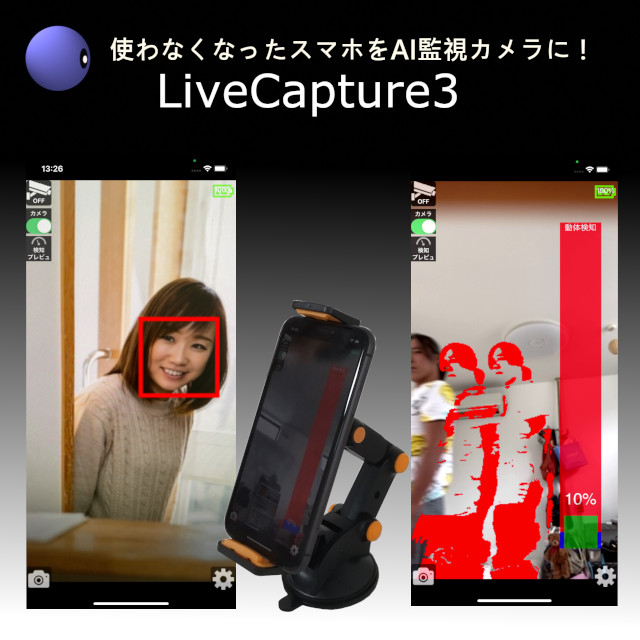
※LiveCapture3(iPhone/Android)の取得はこちらから。

LiveCapture3 (iPhone/Android)には、AI検知機能があります。
この機能は、独自に作成した機械学習モデルを読み込んで、カメラに映った映像をリアルタイムに画像認識処理し、特定のタグに反応した場合にキャプチャーを実行する、というものです。
この機能を使用する為には、まず機械学習モデルを作成する必要があります。
ここではその機械学習モデルの作成方法と、LiveCapture3での使用方法を説明します。
機械学習モデル
LiveCapture3(iPhone/Android)には、機械学習の実行エンジンとしてCoreML(iPhone)・TensorFlowLite(Android)が組み込まれています。
これらの機械学習エンジンに、作成した学習モデルを読み込ませて、カメラに映る映像をリアルタイムに解析させることでAI検知を実行しています。
AI検知を使用する為には、まずこの学習モデルを作成する必要があります。
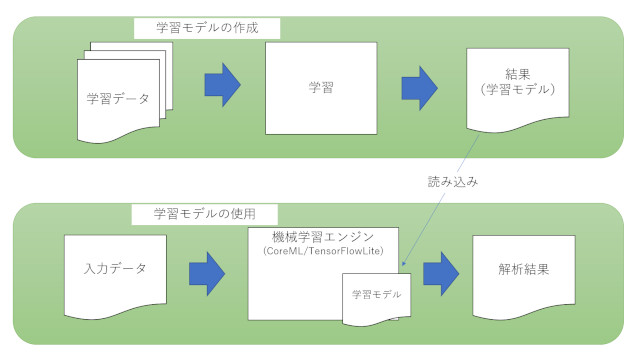
「学習モデル」とは、あるデータ群の傾向や特徴を数式化したものです。
この学習モデルを機械学習エンジン(CoreML/TensorFlowLite等)に読み込ませることで、入力データに対して学習した傾向・特徴に基づいた評価・判定を行うことができます。
一般的な事例としては
- 過去5年間の商品の販売動向を学習データとして学習モデルを作成し、新商品の販売価格を設定する
- 傷のついた商品画像を学習データとして学習モデルを作成し、製造工程で傷のついた商品を検品するシステムの開発
など、様々な評価・判定が可能です。
出力された評価が正しいものかどうかを左右するのは、学習データの質と量、学習モデルの精度などが重要になります。
偏った学習データでは良い学習モデルを生成することはできませんし、それなりのデータ量も必要になります。
また、作成された学習モデルは、学習に使用した学習データに対しては良い性能を表すことが多いのですが、実際に使用する際の入力データ(実データ)に対しても有効であるかを確認しながら、モデルの精度を上げていく必要があります。
一般的には、モデル生成に使用する学習データとは別に、テスト用のデータを用意して、生成された学習モデルの精度を確認する作業が必要になります。
ただ、ここでは、なるべく簡単にそれなりの精度の学習モデルを作成する方法を説明しようと思います。
Azure Custom Vision
LiveCapture3(iPhone/Android)では、カメラのフレーム画像を入力データとした画像解析の機械学習を行います。その為、学習データも画像になりますが、機械学習で画像を学習させるためには、まず画像データを数値化する必要があります。
その辺りを手軽に行ってくれるサービスが、Microsoftが提供しているクラウドサービス Microsoft AzureのCustom Visionという画像解析サービスです。
クラウドサービスなので、アカウントの作成が必要ですが、学習モデルを作成する程度であれば、設定されている無料枠で十分です。
このCustom Visionの良いところは、学習画像を放り込むだけで(とりあえずの)学習モデルが作成されるところです。
また、学習モデルの出力形式として、CoreMLやTensorFlowLiteなど、様々な機械学習エンジン向けの出力フォーマットをサポートしています。
Azure Cognitive Serviceのリソース作成
Azureの無料アカウントを作成して、ポータルにログインすると、下記のようなダッシュボード画面が表示されます。
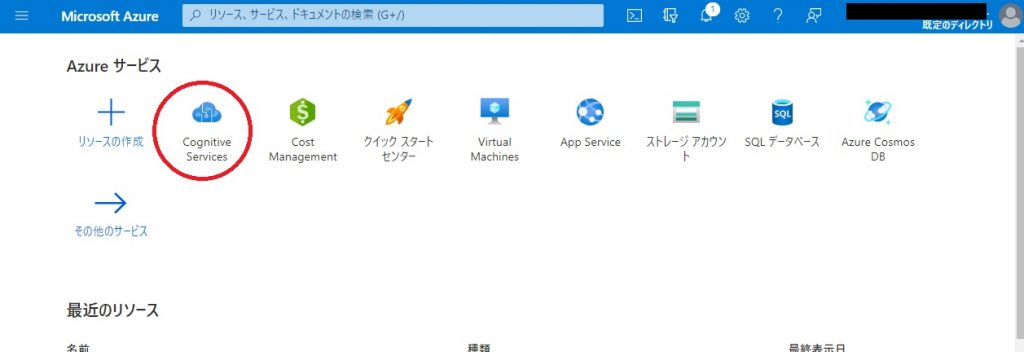
Custom Visionは、赤丸印のCognitive Serviceの機能になりますので、まずはCognitive Serviceを選択します。
選択後、「作成」ボタンを押すと、下記のようなMarketplaceが表示されますので、検索入力に「Custom Vision」と入力してCustom Visionを検索・選択してください。
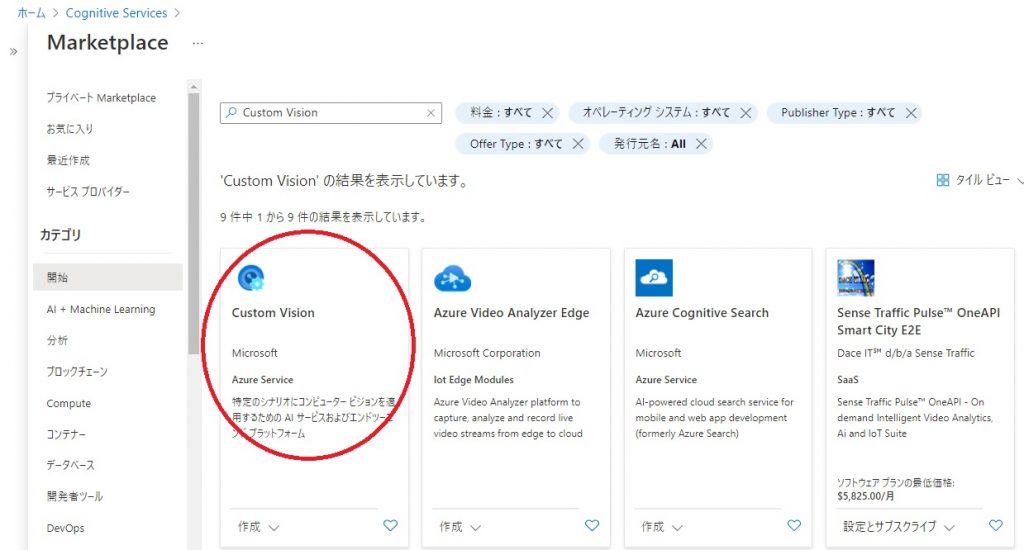
Custom Visionを選択し、「作成」ボタンを押すと、下記のような作成画面が表示されます。
ここでは
- 「作成オプション」:トレーニング
- 「リソースグループ」:新規作成で名称入力
- 「名前」:入力
- 「トレーニング価格レベル」:無料枠の「Free F0」
を選択・入力してCustom Visionリソースを作成します。
リソースを作成すると、ホーム画面上に作成したリソースが表示されます。
学習モデルの作成
学習モデルは、Custom Visionポータルサイト上で作成します。
ホーム画面上に表示されている、先ほど作成したCognitive Serviceのリソース名をクリックすると、下記のようなクイックスタート画面が表示されます。
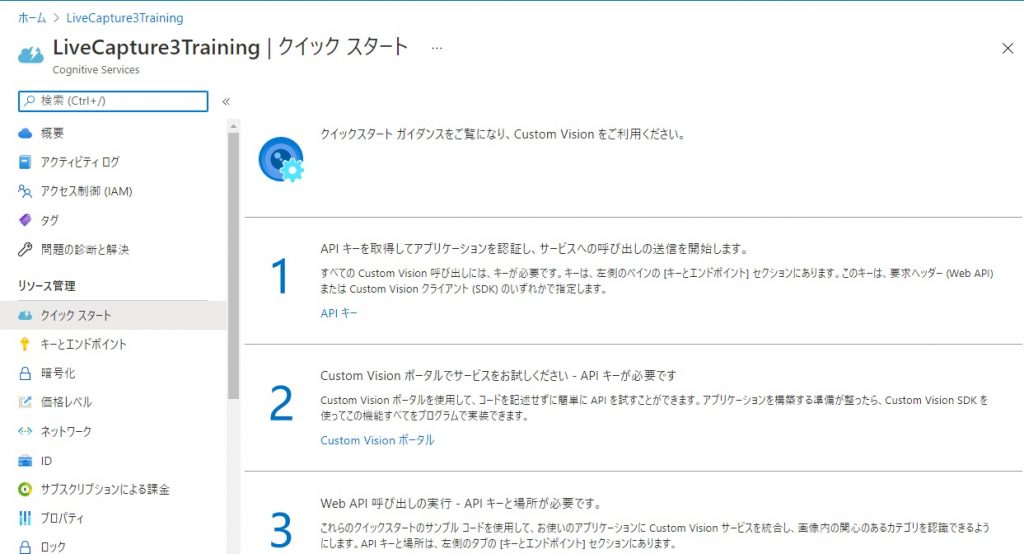
この「クイックスタート画面」の「2」の段に記載された「Custom Visionポータル」を開くと、Web上で画像認識モデルを生成できるCustom Visionポータルが開きます。
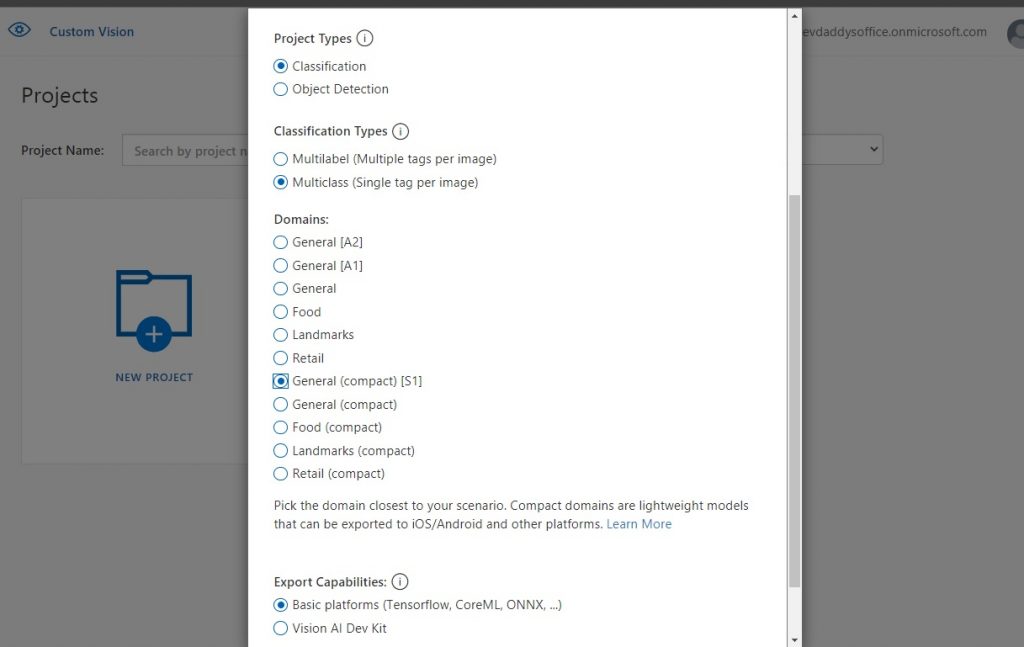
その画面上の「NEW PROJECT」をクリックして、学習モデル作成用のプロジェクトを作成します。
様々なパラメータがありますが、ここではLiveCapture3用のCoreML/TensorFlowLite用のモデルを生成するので、
- 「Project Types」:Classification
- 「Classification Types」:Multiclass (Single tag per image)
- 「Domains」:General (compact)[S1]
- 「Export Capabilities」:Basic platforms
を選択してプロジェクトを作成します。
プロジェクトを作成したら、学習用の画像ファイルをタグをつけて登録していきます。
例えば、犬を判別させるモデルを作成する場合は、犬の画像を「dog」というタグをつけて登録していきます。
無料枠の場合、登録できる画像の数が制限されていますので、その制限を超えないように画像を登録していきます。
ただ、気を付けなければいけないのが、タグの付け方です。
今回のような、分類(classification)問題を機械学習のニューラルネットワークで分析する多クラス分類(Multiclasses classification)の結果は、出力結果の各タグの値の合計は1.0になります。
例えば、犬と猫の写真を「dog」「cat」というタグをつけて登録してできた学習モデルの出力結果は、dog + cat = 1.0になります。つまり、どんな画像を入力しても、dogかcatのどちらかに振り分けられてしまい、正しい判別結果になりません。
なので、犬猫を判別させるモデルを作成する場合は、「dog」「cat」に加えて「other」のようなタグ(否定タグ)を追加する必要があります。
ただ、あまり多くのタグを追加すると、各タグの値の差が小さくなってしまい、これも正しく判別させるのが難しくなります。
このように精度の高いモデルを作成する為には、学習データ含めて、色々と調整が必要になります。
詳しい操作方法やトレーニング方法は下記を参照してください。
学習データの入手について
良い制度の学習モデルを作成するには、大量の学習データが必要になります。
しかも学習データの良し悪しで、学習モデルの精度も大きく変わってきますので、学習データの選び方は非常に重要です。
私は学習データの入手先として下記のサイトを利用しています。
Kaggleとは、世界最大の機械学習コンペティションプラットフォームで、ホスト(企業や大学)が提供するお題とデータに対して、構築するモデルの精度を競い合う為のプラットフォームです。
様々な知見や情報が得られるのですが、それだけでなく、学習データも提供されており、独自のモデル作成の学習データとしても利用可能です。
(利用する際はデータのライセンスをよく理解したうえで利用してください)
学習モデルの出力とLiveCapture3への読み込み
学習モデルが生成できたら、生成した学習モデルを、LiveCapture3で読み込めるCoreML or TensorFlowLite形式に変換して出力します。
Performance画面の上部にした↓アイコンがありますので、これをクリックすると、「Choose your platform」画面が開きます。
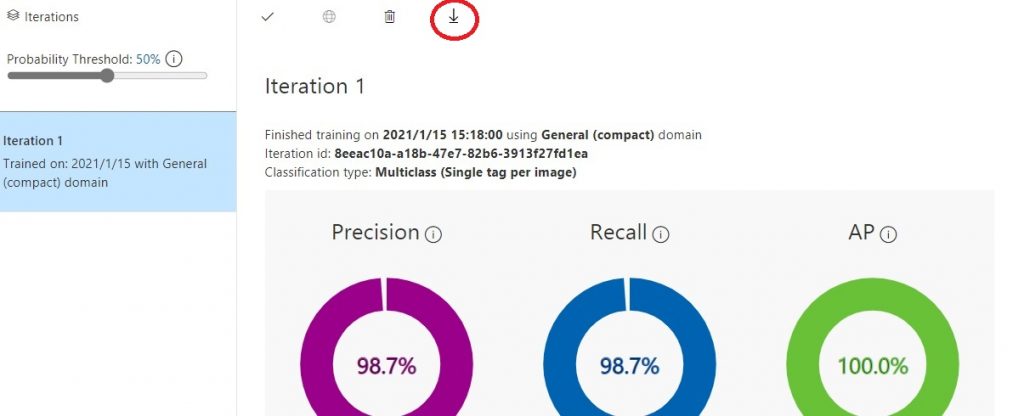

ここで、iPhone用であればCoreML、Android用であればTensorFlowを選択して、モデルファイルをダウンロードします。
※CoreMLは、その後の選択も「CoreML」を選択してください。TensorFlowは、その後の選択で「TensorFlowLite」を選択してダウンロードしてください。
ダウンロードしたZIPファイルを解凍すると、いくつかファイルが含まれていますが、その中で下記の2つのファイルをLiveCapture3(iPhone/Android)で読み込み可能な場所にコピーします。
- 学習モデルファイル : model.mlmodel(CoreML) / model.tflite(TensorFlowLite)
- ラベルファイル : labels.txt
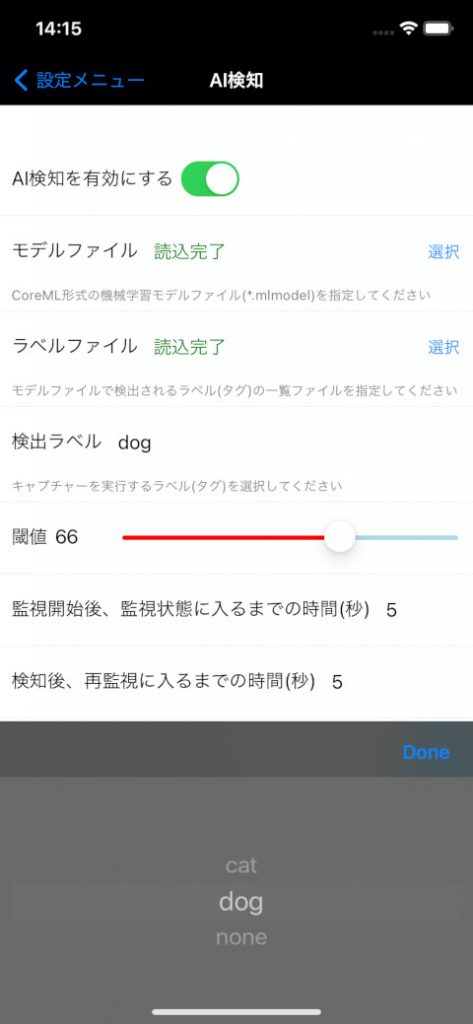
LiveCapture3(iPhone/Android)を起動して、設定 – AI検知を選択して、AI検知画面を開きます。
AI検知を有効にして、上記のモデルファイルとラベルファイルをそれぞれ読み込みます。
読み込みが完了すると、「検出ラベル」が選択可能になりますので、検出したいラベル(タグ)を選択します。
設定が完了したら、メイン画面に戻って、左上にある「検知プレビュー」ボタンを押して、「AI検知」のプレビューを有効にします。
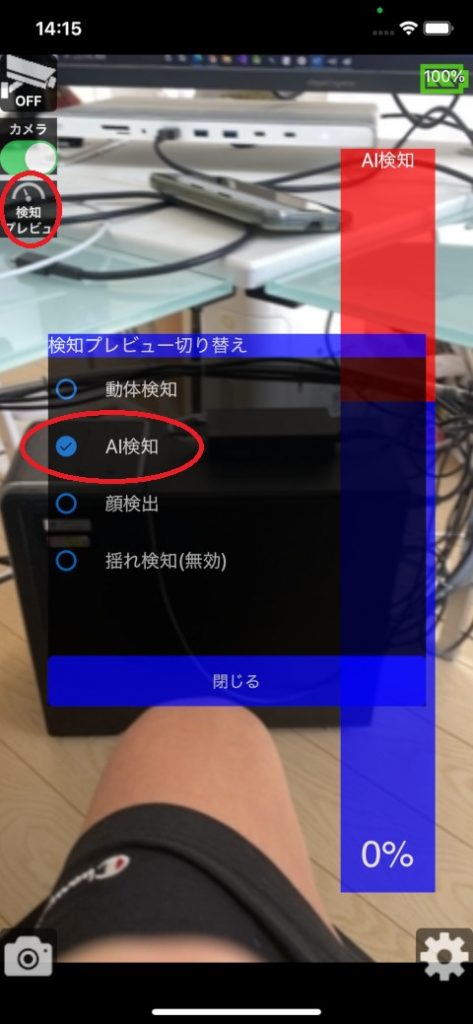
これで、カメラ映像の画像認識の精度をリアルタイムで確認できます。
右側のレベルバーで、選択した検知ラベル(タグ)の検出確率が表示されますので、色々とカメラに映しながらモデルの精度を確認してみてください。
下記の画像は、犬の検出を行うモデルファイルを読み込んで、カレンダーの犬の写真を写したところです。

学習モデルが満足いく精度で生成できたら、キャプチャーアクション(検知した際に実行するアクション)を設定して、メイン画面で監視をONにすれば、AI検知の出来上がりです!
サンプル用学習モデル
以下に私が作成したサンプル用の犬猫判別モデルを置いておきます。
※これらの学習モデルはあくまでサンプル用です。精度の問題などお使いいただく上で不具合があっても質問にはお答えできません。
最後に
Azureのサービスを使用して、LiveCapture3(iPhone/Android)のAI検知用学習モデルの作成方法を説明してきました。
機械学習というと、ちょっと敷居が高いように感じますが、「利用する」方はかなり一般的になってきています。
また、Custom Visionのように、誰でも簡単に学習モデルを生成できるサービスも多々ありますので、これをきっかけに様々なモデルの作成にチャレンジしてみてください。

- Daddy
- クラウド不要のエッジAIレコーダ SmartNVR! 2026年4月1日
- AI熊撃退システム実証実験開始! 2026年4月1日
- AI CAPTUREバージョンアップしました 2026年1月14日
- 新しい監視システムをリリースしました! 2025年10月13日
- ZennでBookを書きました! 2024年10月26日
LC3はソースコードが公開されてないので予測ですが、
・ベイズ理論
・顔の数値化
・KNN予測法
を使ったオフライン方式がWindows向けにあるといいですね
https://github.com/MuntahaShams/Face-recongnition-on-windows/blob/master/code.py
使用例:
・カメラ内に人が入る
・人1 ー 斎藤さん(>80%以上)
・もうひとり入る
・人2 ー ? (または結果<40%)
・人2が不審者 → 画像撮影
LC3 Win向けのAI検知機能は現在実装中です。
ちょっと他案件との兼ね合いでリリースはもう少し先になりそうですので、もうしばらくお待ちください。。。